Automatisches Deployment mit Gitlab-CI
Mit Gitlab-CI kostbare Zeit sparen
Testen, committen, pushen, zu einem Deployment-Tool wechseln, sich dort einloggen, bauen, deployen.
Das kann mühsam sein, vor allem wenn schon mit dem push ein Ende dieser Kette erreichbar ist.
Continious Integration, kurz CI, verfolgt das Ziel, Änderungen des Quelltextes automatisiert zum Kunden zu bringen.
Dieses Ziel wird mit einer Pipeline erfüllt, welche nach einem push durchlaufen wird.
Jobs, Stages und Pipelines
Eine Pipeline kann als eine Abfolge von Schritten begriffen werden.
Sie läuft mehrere Stages in einer bestimmten Reihenfolge ab.
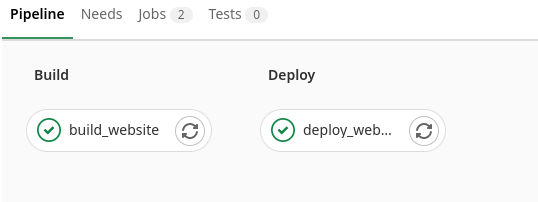
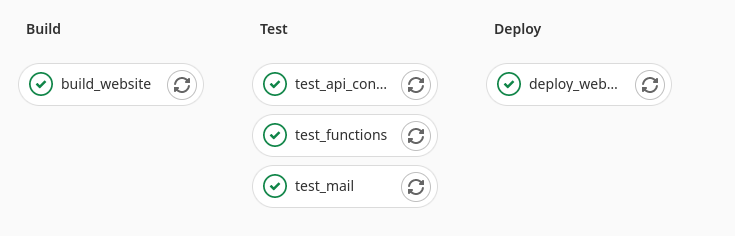
Eine Stage fasst mehrere Jobs zusammen.
So können beispielsweise in einer Ablaufphase mehrere Testfälle abgearbeitet werden.
CI-Variablen
Manchmal ist es nötig, bestimmte Daten zu übergeben.
Arbeitet man etwa mit einer API, ist oft ein Token nötig, um eine Verbindung aufzubauen.
Gitlab bietet die Möglichkeit, Variablen anzulegen und später zu nutzen.
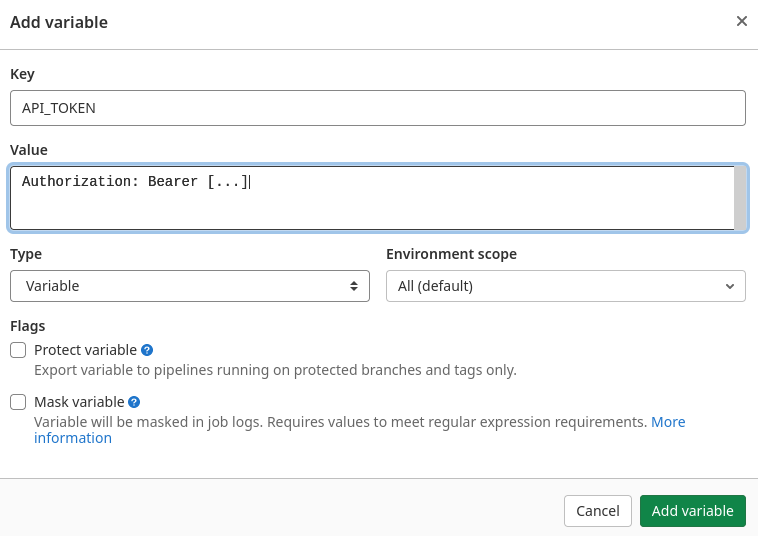
Zu finden ist diese Einstellung in den Projektoptionen unter Settings -> CI/CD -> Variables.
Möchte man diese Variable später in der gitlab-ci.yml nutzen, ist sie unter $API_TOKEN anzusteuern.
Der Gitlab Runner
Soeben beschriebene Pipelines werden von sogenannten Runnern ausgeführt.
Sie nehmen die Anweisungen aus der gitlab-ci.yml entgegen und setzen diese um. Je nach Konfiguration können mehrere Runner zur selben Zeit arbeiten.
Aufbau einer gitlab-ci.yml
Praktischerweise stellt Gitlab von selbst die Gültigkeit einer gitlab-ci.yml fest.
Bei fehlerhafter Syntax wird automatisch eine Fehlermeldung ausgegeben und die Ausführung ist unmöglich.
Wie es sich für eine Datei vom Typ YAML gehört, gelten auch hier die gängigen Syntaxregeln.
Hier werden Jobs und Stages definiert, aus welchen sich die Pipeline zusammensetzt.
job_name:
stage: build
Zuerst wird der Job mit einem beliebigen Namen versehen und einer Stage zugeführt.
Standartmäßig sind folgende Namen für eine Stage zulässig. Bei Missachtung nimmt Gitlab die gitlab-ci nicht an.
| Name | Nutzung |
| .pre | Aufgaben, die eventuell vor dem Prozess zu erledigen sind |
build | Alles für das Projekt Nötige installieren |
test | Den Quelltext auf Funktionalität prüfen |
| deploy | Das Projekt in neuer Fassung ausliefern |
| .post | Eventuelle Nacharbeiten, z.B. eine Bereinigung |
Es ist allerdings möglich, eigene Namen für eine Stage zu definieren.
Nun wird das offizielle Docker-Image von Docker selbst heruntergeladen und durch dind ergänzt.
Dies wird erwirken, dass der Docker-Container in einem Docker-Container läuft und nicht direkt auf dem Hostsystem.
Dadurch wird es nach Ausführung der Pipeline keine Überbleibsel mehr geben.
image: docker:latest
services:
- docker:dind
Der Bereich script wird genutzt um reguläre Befehle auszuführen.
In diesem Beispiel wird abfolgend:
- ein Login zur lokalen Docker Registry hergestellt
- der aktuelle Branch gepullt
- das zugehörige Image gebaut
- und schließlich in die Registry für den weiteren Gebrauch hochgeladen
Das alles Unterliegt der Bediungung, dass im aktuellen Branch ein Dockerfile vorhanden ist.
script:
- docker login -u "$CI_REGISTRY_USER" -p "$CI_REGISTRY_PASSWORD" $CI_REGISTRY
- docker pull $CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG || true
- docker build --cache-from "$CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG" --pull -t "$CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG" .
- docker push "$CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG"
rules:
- if: $CI_COMMIT_BRANCH
exists:
- Dockerfile
Da das Projekt gebaut wurde, kann es nun auf das Zielsystem gebracht werden.
deploy_website:
stage: deploy
image: $CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG
before_script:
- apt update && apt -y install openssh-client
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | ssh-add -
- mkdir -p ~/.ssh
- echo -e "Host *\n\tStrictHostKeyChecking no\n\n" > ~/.ssh/config
script:
- ssh root@<IP> "cd docker/blogeintrag-beispiel && docker stop form && docker rm form && git pull && docker build --no-cache -t form . && docker run -d -p 80:80 --name form form && exit"
Im Deploystadium wird das gepushte Image heruntergeladen und ein letztes Mal konfiguriert.
Ausgehend davon, dass das Projekt bereits auf dem System installiert ist, geschieht Folgendes:
- die Paketlisten werden aktualisiert, damit die Suche nach Paketen erfolgreich wird
- der SSH-Client wird installiert, damit sich das Image mit dem Zielsystem verbinden kann
Danach wird:
- eine Verbindung zum Zielsystem aufgebaut
- in das Projektverzeichnis gewechselt
- der aktuelle Stand aus der Versionsverwaltung geladen
- der zuständige Docker-Container gestoppt und gelöscht
- das Docker-Image neu gebaut und gestartet
- die Verbindung geschlossen
Simples HTML Beispiel
Zur Veranschaulichung ein kurzer Videoclip.
Hier wird einem Formular welches einen Nutzernamen und ein Passwort abfragt zusätzlich ein Feld zur Abfrage einer E-Mail Adresse beigefügt.
Diese Änderung wird commited und gepusht, dazu wird die gitlab-ci.yml aus dem vorherigen Beispiel verwendet.

Schlusswort
Warum eine weitere Instanz pflegen und administrieren, wenn es die Versionsverwaltung auch tut? Möglicherweise hat das Deployment-Tool sogar einen Ausfall und muss während des Deployments noch repariert werden, wodurch wertvolle Zeit verloren geht.
Nach einer kurzen Einarbeitungsphase kann jedes Team von Gitlab-CI profitieren.
Wenn ihr Fragen habt, meldet euch: info@mobilistics.de